Nuestros tests como un usuario más del sistema
No os engaño, quiero hablaros del código testable. No de tests, sino del código de producción fácilmente testable. Pero intentaré darle un enfoque diferente. ¿Por qué? Creo que, en función de cómo vemos un problema, así buscamos una solución acorde al mismo. Por lo tanto, plantearnos el problema de manera que nos atraiga puede hacernos más llevadero intentar resolverlo.
Veo una y otra y otra vez cómo se ponen en distintos lados de la balanza entregar funcionalidad, hacer código mantenible y probar nuestro sistema. Luego cada cual defiende su postura como por ejemplo:
- Es que no está reñido hacer código de calidad y automatizar tests.
- Es que si no automatizo tests no puedo hacer código de calidad.
- Es que si tengo que complicar mi código para poder probarlo…
- Es que si nos ponemos a hacer tests no llegamos.
- Es que a mi no me dejan probar.
- …
Entonces, ¿qué cambia en el planteamiento de que nuestros tests sean un usuario más del sistema? Yo creo que nuestra forma de replantearnos las necesidades que nuestro software debe cumplir. Los usuarios, además de utilizar nuestro sistema, también tienen necesidades sobre el mismo. De entre todas ellas, quiero hablar de una que está socialmente bastante aceptada. La usabilidad. Sin entrar en si por usabilidad me refiero a UX, accesibilidad, o cualquier otra acepción… quiero definir la usabilidad como la cualidad que hace que sea cómodo usar nuestro sistema.
Con este planteamiento espero convencer sobre todo a aquellas personas que se dedican a la parte más visible del software y que en mi experiencia suelen ser más reacias a hacer tests ya que los test de UI son más complejos, más lentos, más costosos y más de todo :S. Pero a su vez son las personas con más criterio y que más importancia le dan a la usabilidad.
Usabilidad desde la perspectiva de los tests
Un test automático, básicamente ejerce de usuario de la parte de nuestro sistema que queremos probar. Y como tal deberíamos preocuparnos de sus requisitos de usabilidad.
¿Pero esto no contradice el principio que dice que nuestro código de producción no debe verse afectado por nuestros tests? Si y no. Efectivamente, el simple hecho de plantearnos hacer código testable, por definición, hará que nuestro código de producción se vea afectado. A partir de ahora, intentaré convenceros de que esos cambios son para bien :). Y de hecho, como veremos, la mayoría de esos cambios ya se plantean como la forma de hacer código mantenible y, en definitiva, limpio.
Los tests, como usuarios de nuestro sistema no requerirán, a priori, ninguna funcionalidad nueva. En principio están interesados únicamente en probar los casos de uso que ofrece el sistema. Y, como decía, suele estar desaconsejado escribir funcionalidad específica para los tests (siempre puede haber excepciones). Sin embargo, como usuarios de nuestro sistema podrían tener requisitos de usabilidad.
En algunos casos, los que menos, serán requisitos específicos de los tests, pero en general, dichos requisitos mejorarán la usabilidad para otros usuarios :).
Si he conseguido convencerte de este planteamiento y te hace ver los tests de otra manera, me doy por satisfecho y te puedes ahorrar el resto del post :P. Aunque te adelanto que intentaré dar algunos ejemplos concretos en distintas situaciones que a mi me han ayudado.
Usabilidad en tests de UI
Hay una escuela bastante fuerte que nos dice que los tests de UI son frágiles y debemos evitarlos. En general estos tests, además suelen probar el sistema entero, por lo que añadimos, a la complejidad de probar mucho software de golpe, la fragilidad de atacar directamente a la UI. Y la lentitud de nuestros tests.
Para intentar rebatir, parcialmente, el argumento de la fragilidad, intentaré convenceros con esta analogía: la interfaz de nuestro sistema es el equivalente a la signatura de nuestros métodos. Es nuestro contrato. Si éste, es demasiado rígido, ante cualquier cambio, es susceptible que rompamos cada test o cada interacción que habíamos implementado. Y del mismo modo que con la signatura de nuestros métodos llevamos a cabo ciertas prácticas para que sean más robustas ante cambios, como utilizar parámetros con valores por defecto, encapsular conjuntos de parámetros en objetos, etc. También podremos aplicar ciertas técnicas en el caso de la UI que hacen que nuestros tests sean más robustos.
Intentaré contar el escenario menos usable que me he encontrado con una interfaz gráfica y trataré de poner ejemplos de menos a más usables.
1. Pixeles
Una vez me plantearon automatizar pruebas para un videojuego móvil a nivel UI escrito con Unity. Nada muy sofisticado, simplemente asegurar que el juego no crashee al arrancar y poco más. Tras investigar un poco, vi que no tenía manera de acceder a ningún elemento de la pantalla más allá de presionar un pixel concreto. Os podréis imaginar lo robustas que pueden ser esas pruebas. El más mínimo cambio en la UI o, incluso en el dispositivo en el que se ejecutan las pruebas lo rompe todo. Del mismo modo, imaginaos las aserciones… screenshots capturadas en pantallas muy dinámicas donde no es fácil asegurar que la captura se haga siempre en el mismo momento.
Desde la perspectiva de nuestros tests… es muy incomodo interactuar con nuestra aplicación. Creo que, debido a cómo ejecutan estos motores los juegos, no están muy pensados para ser probados así y mi conocimiento (nulo) de desarrollo de videojuegos me impide aportar una solución mejor, pero creo que hay poco margen de mejora a nivel de UI interactuando en un dispositivo.
A partir de aquí, para poder hablar con un poco menos de abstracción intentaré poner un ejemplo concreto para que veáis a qué me refiero:
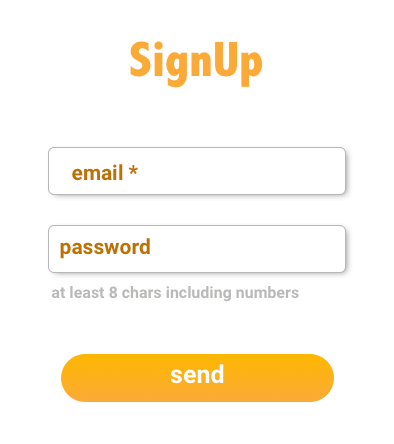
2. Elementos sin identificar
Este es un ejemplo tipiquísimo en webs. Recuerdo que las primeras pruebas que me tocó automatizar de esta manera eran sobre un software que no estaba para nada pensado para este tipo de pruebas, además utilizaban componentes empaquetados. ¿Qué quiere decir esto? Que ningún elemento tenía, ni ids, ni selectores css ni nada con lo que identificar el elemento concreto. Es decir, que disponíamos del DOM, pero para interactuar con los elementos había que hacer cosas del estilo de: "haz click en el quinto div después de la tercera lista". O "el link que tiene como texto...".
De esta forma nuestra pantalla de login podría tener el siguiente html
<ul>
<li>
<input placeholder="email*" type="text"/>
</li>
<li>
<input placeholder="password" type="password"/>
<p>at least 8 chars including numbers</p>
</li>
<li>
<button>send</button>
</li>
</ul>
Al no tener identificadores ni nada del estilo, tendría que buscar los elementos con queries del tipo:
- El input de tipo password.
- El primer input de tipo texto.
- El elemento de tipo button
Pero, ¿qué pasa si ahora me piden poner el nombre en el formulario de signup? Seguramente mi navegación se rompería. O si decido utilizar un elemento de tipo form y enviar los datos con un <input type="submit">.
Con este panorama, cualquier cambio en la UI rompía los tests. O bien su interacción o bien sus aserciones.
3. Elementos identificados
Actualmente le damos más importancia a temas como la accesibilidad y por lo tanto marcamos de una manera u otra los elementos importantes de nuestra UI. Esto hace que sea mucho más fácil interactuar con nuestra interfaz y hacer verificaciones sobre ella.
De esta forma nuestra pantalla de login podría tener el siguiente html
<form>
<li>
<input placeholder="email*" type="text" name="email" id="email"/>
</li>
<li>
<input placeholder="password" type="password" name="password" id="password"/>
<p>at least 8 chars including numbers</p>
</li>
<li>
<button id="signup">send</button>
</li>
</ul>
Ahora no tenemos más que buscar los elementos por su identificador o su nombre y el hecho de que se cambie la estructura del html no debería afectar tanto a nuestros tests.
Como decía, he ido mostrando de más complicado a más sencillo el interactuar con la UI. Es verdad que para el primer caso no tengo solución :S, pero en caso de interfaces web o de dispositivos móviles, el hecho de hacerlas más usables para nuestros usuarios, la hacen más usables para nuestros tests y viceversa.
Otras consideraciones
Por otro lado, partiendo de la usabilidad como premisa, veamos como afectan a que nuestro sistema sea más fácilmente testable:
Si, como usuario tengo que ejecutar un montón de pasos para llevar a cabo un flujo, muy probablemente escribir un test me resultará bastante tedioso. En este caso, si le diéramos importancia a automatizar tests, con la excusa de simplificarnos un poco la vida, probablemente se la acabaríamos simplificando también a nuestro usuario final. Dicho de otra manera… mentalmente, el coste de simplificar algo, nos puede parecer innecesario si no va aportar valor visible. Y si no somos usuarios de nuestro producto (cosa bastante habitual), quizás no seamos conscientes del valor de simplificar ciertos flujos. Pero si nos convertimos en usuarios a través de nuestros tests, es posible que empecemos a tener una ventaja visible a dicha simplificación. Soy consciente de que al final, los flujos los suele definir producto. Pero también he visto muchas veces como producto nos transmite lo que hay que hacer y si no nos parece bien, lo discutimos hasta el aburrimiento.
Usabilidad en tests que prueban nuestros métodos
En este caso estamos hablando de APIs, por lo tanto, los usuarios de nuestros métodos somos la misma persona/equipo que desarrolla. Visto así la usabilidad debería ser prioritaria por la cuenta que nos trae.
¿Y qué quiere decir usabilidad en mis métodos?
- Que el código que quiero probar no haga demasiadas cosas diferentes.
- Que el código que quiero probar tenga muchísimos caminos posibles.
- Que la signatura de mis métodos sea honesta.
- Que tengo capacidad de decisión sobre la porción exacta de código que quiero probar.
- Que no tengo que montar la marimorena para obtener una instancia de eso que quiero probar.
- Que no tengo que llamar a 450 métodos antes de llamar a los métodos que en realidad quiero probar.
- Que no tengo que crear un dataset costosísimo de crear con cada test.
Intentaré desarrollar un poco más cada punto desde el punto de vista de lo que puedo hacer en mi código de producción para simplificar. En otro post que estoy preparando hablaré de cómo mitigar esto desde el punto de vista de los tests.
Que el código que quiero probar no haga demasiadas cosas diferentes o tenga muchísimos caminos posibles
El incumplimiento del principio de responsabilidad única (la S de SOLID) es quizás uno de los mayores enemigos del código fácilmente testable. Y este punto hace alusión directa al mismo. Si el fragmento de código que quiero probar hace muchas cosas diferentes, es muy probable que tenga que escribir, o bien tests muy complejos, o muchos tests.
Del mismo modo, cuando nos enfrentamos a un código con demasiada complejidad ciclomática, es decir, con mucha ruptura de secuencia y por lo tanto muchos flujos de ejecución posibles, nos resultará tedioso de probar. No es lo mismo probar un fragmento que tiene un if con 50 ramas diferentes incluso con condiciones anidadas, que un fragmento de código secuencial puro.
La complejidad ciclomática determina el mínimo número de tests diferentes que tengo que realizar/implementar, para probar completamente un trozo de software, por lo tanto nos interesa reducirla lo máximo posible para reducir la cantidad de tests que debo realizar.
En los dos casos comentados, nos enfrentamos a código con una carga cognitiva potencialmente grande. De ser así, es posible que nos agobie pensar qué y cómo probar. De hecho, es muy probable que directamente nos agobie intentar deducir que está haciendo exactamente ese código. Y si no somos capaces de razonar qué hace ese código, muy probablemente no seremos capaces de definir un buen conjunto de pruebas.
Por el contrartio, normalmente, descomponer nuestro código en fragmentos pequeños, con alta cohesión y con un propósito único y sencillo, hará que no tengamos que pensar en demsaidas cosas para trabajar con él. Y por lo tanto probarlo será también más sencillo ya que no tendremos que tener en la cabeza estructuras demasiado complejas.
Que la signatura de mis métodos sea honesta
Veamos este punto con un ejemplo práctico:
fun signUp(user: User)
vs
sealed class SignUpResult
data class DuplicatedUserError(user: User): SignUpResult
data class ValidationError(errors: List<Error>): SignUpResult
data class CreatedUser(createdUser: User): SignUpResult
fun signUp(user: SignUpRequest): SignUpResult
En el primer caso vemos que no tenemos apenas información de lo que puede suceder durante el signUp. Mientras que en el segundo caso nos hacemos una idea de la posible casuística ya que la signatura nos está dando muchas pistas. Por lo tanto nos será mucho más fácil plantear una prueba de tipo caja negra con la segunda signatura que con la primera.
Simplemente viendo las signaturas, para el primer caso se me ocurriría hacer una sola prueba, mientras que en el segundo caso, sé que, al menos debería probar tres flujos diferentes.
Además, las aserciones serán más sencillas con la segunda signtaura, ya tengo toda la información contenida en la misma. De este modo tengo acceso a toda la información que necesito como resultado de la ejecución de mi método.
En el primer caso, sin embargo, tendría que ver cómo conseguir información del usuario recien creado si quisiera verificar, por ejemplo que se le ha asignado un id. O que su password no está guardada en plano (por poner ejemplos típicos de un signup).
Que tengo capacidad de decisión sobre la porción exacta de código que quiero probar
Si amiguis, estamos hablando de cómo preparar mi código para reemplazar los componentes que no me interesa probar por dobles de prueba. En este caso, la forma más típica es recurrir a la inyección de dependencias, aunque hay lenguajes que ofrecen otros mecanismos para cortar por donde me interesa. Please, no confundamos inyección de dependencias con el inyector de dependencias.
¿Qué ventajas tiene la inyección de dependencias?
- Puedo identificar fácilmente quienes son mis colaboradores externos rápidamente.
- Consecuencia de esto, puedo ver cómo de complejo/acoplado está mi código.
- Tiendo a depender de abstracciones en lugar de concreciones.
- Puedo reemplazar el comportamiento de dichos colaboradores.
¿Qué desventajas tiene?
- Para quienes no estemos acostumbrados a esta forma de trabajar, no resultará un pelín más anti-intuitiva.
- Crear una instancia concreta tiende a requerir más boilerplate ya que debo crear previamente todas sus dependencias, lo cual nos lleva al siguiente punto.
Que no tengo que montar la marimorena para obtener una instancia de eso que quiero probar
Como comentaba en el punto anterior, si requerimos de un montón de dependencias para inicializar nuestro SUT (subject/system under test), es probable que nos acabe por dar mucha pereza.
Es importante identificar cuando tenemos muchísimas dependencias,ya que es muy probable que estemos violando el principio de responsabilidad única.
De ser este el caso, podríamos plantear si nuestra clase podría dividirse simplificando así también su árbol de dependencias. Un buen identificador podría ser verificar si tenemos dependencias opcionales. De ser así, es muy posible que nuestra clase se pudiera partir. En general hacer esto no es una tarea especialmente compleja y los IDEs nos ayudan bastante así que no debería suponer un gran problema.
Desde el punto de vista del código de producción se me ocurre poco más que podamos hacer en este aspecto, pero si tenéis sugerencias, por favor comentadlas ;). Como decía, estoy preparando otro post para dar ideas sobre como mitigar esto en nuestros tests.
Que no tengo que llamar a 450 métodos antes de llamar a los métodos que en realidad quiero probar
En general, la necesidad de hacer muchas llamadas previas se debe a que necesito generar un estado concreto para que mi código pueda funcionar. En este aspecto se me ocurren dos escenarios:
- Estado local dentro de una clase: Es fácilmente identificable cuando requerimos que nuestros objetos, una vez creados, deban llamar a un método de tipo
init. Esto en general es una mala práctica y en la medida de lo posible, nuestras clases deberían ser stateless y recibir el estado que necesitan para funcionar, o bien en el momento de la creación o bien durante la llamada al método que necesita dicho estado. Por ejemplo:class UserValidator() { private var user: User? = null fun init(user: User) { this.user = user } fun validateCanBeCreated(): Bool { //do the validation with this.user } }vs
class UserValidator() { fun validateCanBeCreated(user: User): Bool { //do the validation with user } }En este caso, no solo es que el código de producción será menos testable en el primer caso. Es que además será muchísimo más propenso a errores. Y aunque hay quien podría pensar que es caso llevado al extremo, lo he visto más de una y dos veces en código de producción.
- Estado global del sistema: En tests con un scope grande o que atacan a sistemas externos como podría ser nuestro storage (base de datos, APIs, etc.) podemos encontrarnos con este problema. Creo que aquí la solución mas típica/evidente vendría dada por cambiar el alcance del test, aunque, como digo, en la medida de lo posible, tener clases y métodos stateless que reciben lo que necesitan para trabajar, nos ahorra mucho tiempo.
Además, cuando el código afecta al estado global del sistema de manera intensiva, es muy posible que el tear down de nuestros tests se complique ya que es deseable que el sistema quede en el mismo estado tras la ejecución de un test. De no cumplir con esta propiedad, más temprano que tarde, nuestra suite de test se vuelve inestable ya que el estado modificado por un test podría afectar a la ejecución de otros tests ejecutados posteriormente.
Que no tengo que crear un dataset costosísimo de crear con cada test o, del mismo modo, que no tengo que llamar a mis métodos con 57 argumentos
Yo creo que en este punto y en el anterior se encuentran la mayoría de las líneas de código de test aburridas de escribir :S.
fun userIsValidForCreation(userName: String, email: Sring, password: String, repeatPassword: String, name: String, lastName: String, birthday: DateTime, ...)
vs
data class User(
val userName: String,
val email: Sring,
val encodedPassword: String?,
val name: String,
val lastName: String,
val birthday: DateTime
)
data class CreateUserRequest(
val user: User,
val password: String,
val repeatPassword: String
)
fun userIsValidForCreation(request: CreateUserRequest)
En la primera versión, cada vez que quieras llamar al método tendremos que pasarle un montón de parámetros que hace que tengamos que escribir mucho código de mecanógrafo.
En la segunda versión solo un parámetro, que si bien es cierto que podría llegar a ser tedioso de inicializar, podríamos hacer uso de patrones creacionales como Builders o MotherObjects para simplificar la tarea.
Además esto tiene la ventaja de que nuestros tests suelen ser más robustos ya que la signatura de los métodos no cambia con tanta frecuencia. En el primer caso si, por ejemplo, quisiera añadir la localización de nuestro user, habría que tocar en todos los sitios donde se llame a este método, mientras que en el segundo caso el método seguiría igual.
Usabilidad en cualquier test
Finalmente me gustaría hablaros de otros aspectos de nuestro software de producción que hacen que sea más usable desde el punto de vista de las pruebas (ya sean manuales o automáticas).
-
¿Cómo de complejo es levantar todo mi sistema para poder usarlo? De no ser cómodo, debería invertir más esfuerzo en facilitar este proceso ya que si, como devs, nos cuesta trabajo arrancar el sistema, es muy probable que no probemos lo que hacemos ni siquiera a mano.
-
¿Puedo probar las cosas antes de ir a producción? Suena obvio, pero si nuestra capacidad de testar nuestro sistema no forma parte de los requisitos, no puede suceder que no podamos probar, por ejemplo nuestro proceso de pagos hasta llegar a producción, porque no hemos tenido en cuenta que necesitamos un sandbox.
-
¿Me resulta fácil cambiar la configuración de mi sistema? Si no somos capaces de sobreescribir nuestras configuraciones, es posible que no podamos probar determinadas funcionalidades hasta no estar en producción. O lo que es peor, probarlas y alterar entornos de producción.
Conclusiones
Creo que nadie discute que las necesidades de los usuarios son algo que marca las prioridades del desarrollo, por lo tanto creo que ver nuestros tests como usuarios nos ayudará a:
- Darle más importancia probar nuestro software.
- Esforzarnos por hacer código más testable.
- Como testers, nos convertiremos en usuarios del sistema y podremos criticarlo/empatizar con él más fácilmente. Esto es especialmente interesante cuando hacemos software que no usamos en nuestro día a día.
- Hacer código testable no suele ser incompatible con hacer código mantenible sino todo lo contrario.
- Hacer código testable no implica necesariamente automatizar toda nuestra suite de tests, sino en permitirnos hacerlo si lo llegamos a necesitar.
- En el caso de hacer librerías internas/SDKs, pensar en que sea fácil de probar y fácil de usar es básicamente lo mismo.
Creo que todas las mejoras propuestas para hacer nuestro código más usable, son coherentes con todas esas practicas que nos dicen que harán nuestro software más fácil de comprender, mantener y modificar.
Y seguro que me dejo muchas cosas, pero lo voy a dejar aquí de momento. Muchas gracias a las personas que hayáis aguantado hasta el final. Siento haberme extendido tanto :S