Reduciendo boilerplate al crear nuestras entidades de dominio
La mayoría del código que usaré en este post, corresponde a código real de proyectos reales. Copiado y pegado tal cual está. Solo usaré código inventado cuando no encuentre ningún ejemplo ilustrativo.
Este es el tercer post de la serie “Los test también son código”, me gustaría contaros cómo consigo yo instancias de mis objetos para poder probar. Como los tests son código y hay un montón de formas diferentes de escribir buen código, antes de empezar, quiero insistir en que así es cómo lo hago yo, lo cual no quiere decir os funcione igual de bien. Pero como siempre, si os aporta ideas, este post habrá cumplido su propósito con creces :).
Como decía en el post anterior, donde hablaba de las 4 fases de los tests, la mayoría de las veces es en la primera fase, la del setUp, donde se nos va la mayor parte del código es por ello por lo que he querido que este post sea de los primeros. Pero, ¿cómo influyen las entidades de dominio en esto? Pues bien, posiblemente necesitaremos estos objetos para:
- Los argumentos de los métodos que recibe el código que queremos probar.
- El resultado devuelto por el código que estamos probando y sobre el que tendremos que hacer aserciones. En general la aserción tendrá pinta de
resultObject shouldBe expectedObject. - Los argumentos que reciben los mocks, en el caso en que queramos sobreespecificar verificando TODAS las interacciones.
- Los valores que devuelven nuestros mocks.
Entidades de Dominio y Value Objects
Dejando de un lado todas las razones por las cuales no es deseable que nuestro código lidie con un montón de tipos básicos como argumentos, lo que solemos hacer es agrupar dichos tipos básicos en entidades de dominio o value objects para aportar semántica a nuestro código. Siguiendo esta práctica lo habitual en nuestros proyectos es que acabemos teniendo alguna entidad que contiene un montón de datos. Si por ejemplo hiciéramos Netflix, seguramente tendríamos una entidad Video que lo asumiría todo. O la entidad Tweet o User… Si no tenemos cuidado tienden a contener una cantidad ingente de datos. Por si no os hacéis una idea os dejo un par de ejemplos de proyectos en los que he estado (ya no hay NDA que valga :P) y donde yo tenía capacidad de decisión sobre el código y favorecí llegar a esta situación:
class Wopp {
protected $id;
protected $slug;
protected $description;
protected $event;
protected $image;
protected $shareImage;
protected $video;
protected $videos;
protected $duration;
protected $views;
protected $watchedTime;
protected $creationDate;
protected $deletedSince;
protected $owner;
protected $comments = array();
protected $type;
protected $status;
protected $rewopps = array();
protected $wows = array();
protected $banRequests = array();
protected $slugCandidate;
protected $rating;
protected $answers = array();
protected $answerTo;
protected $coordinates;
protected $distance;
}
o este otro ejemplo:
class ContentNode {
protected $id;
protected $slug;
protected $contentId;
protected $type;
protected $title;
protected $year;
protected $cast;
protected $awards = array();
protected $rating;
protected $runtime;
protected $website;
protected $originalLanguage;
protected $videoAsset;
protected $color;
protected $ranking = 0;
protected $calculatedRanking = 0;
protected $staffRanking = 9999;
protected $playbackCounter = 0;
protected $externalData;
protected $distributor;
protected $genres = array();
protected $categories = array();
protected $localized;
protected $status = self::STATUS_DRAFT;
protected $paymentOptions;
protected $popularityUp = 0;
protected $popularityDown = 0;
protected $popularityNeutral = 0;
protected $popularity = 0;
protected $releaseDate;
protected $platformReleaseDate;
protected $defaultLocale = 'en';
protected $dates;
protected $contentAssetAvailability;
}
* Por reducir espacio, he eliminado getters, setters, comentarios con el type hinting, métodos auxiliares, etc. Pero tened en cuenta que campos como,
$owner,
$comments,
$rewops,
$videoAsset,
$awards, etc. son objetos embebidos que también tienen su montoncito hermoso de campos que rellenar.
Sin entrar en como corregir esto a nivel de código de producción, os diré como lo solvento yo en los tests.
Para evitar un montón de código poco didáctico y por seguir con el ejemplo del post inicial vamos a partir de una entidad con un número moderado de campos, pero que ya sea incómoda de manejar en cada test (sacada del proyecto más reciente con el que he trabajado_):
data class User(
val id: String,
val email: String,
val firstName: String,
val lastName: String,
val imageUrl: String?,
val roles: Set<Role>,
val creationDate: DateTime,
val enabled: Boolean,
val sessionToken: String?
)
Si no pensamos en ninguna abstracción, vamos a tener que inicializar este objeto con 9 valores cada vez. Y más allá de lo incómodo que es escribir este código, es que cada vez que lo inicialicemos tendremos que tomar la decisión de qué valores concretos usar. Y esto es más problemático aún, cuando esa decisión sobre los valores la hacemos sin pensar mucho en las implicaciones de usar un valor u otro.
- En tiempo de escritura, probablemente nos dejaremos casos sin probar.
- En tiempo de lectura, probablemente dediquemos tiempo cada vez a ver si esos datos concretos son relevantes o podría valer cualquiera. Y lo que es peor, se nos pasarán por alto los valores que sí son relevantes.
Esto supone una carga mental lo suficientemente grande para resultar incómoda y lo suficientemente sutil como para pasar desapercibida. Con semejante panorama, lo que sucede es que escribir tests nos puede producir una fatiga que no sabemos explicar.
Además, en la práctica, el punto 1 hace que nos de pereza escribir tests. Y el punto 2 da argumentos poderosos a la archiconocida situación de es que a mi no me dejan probar porque “Ya no es que tú pruebes. Es que tengo que mantenerlos yo”.
- Vale, supongamos que me convences, ¿de qué mecanismos disponemos para mitigar esta situación?
Builders
A mi esta es la opción que menos me gusta, así que no la suelo usar, pero la cuento porque, quizás en vuestro caso sea útil. Los builders nos permiten inicializar objetos de una manera más fluida. Así podríamos settear valores de manera independiente o por grupos. Por ejemplo:
class UserBuilder() {
private var candidate = User(
id = "anyId",
email = "anyEmail",
firstName = "anyFirstName",
lastName = "anyLastName",
imageUrl = "http://anyImage.url",
roles = listOf(Role.Admin),
creationDate = DateTime(0),
enabled = true,
sessionToken = "irrelevantSessionToken"
)
fun withId(id: String) {
candidate = candidate.copy(id = id)
}
fun withEmail(email: String) {
candidate = candidate.copy(email = email)
}
//... no pongo el resto de campos por simplificar
fun withLoginInfo(email: String, sessionToken: String) {
candidate = candidate.copy(
email = email,
sessionToken = sessionToken,
enabled = true
)
}
fun build(): User = candidate
}
Y entonces podría usarlo de la siguiente manera:
val userThatIsLoggedIn = UserBuilder()
.withId(id)
.withLoginInfo(email="sergio@serch.dev", sessionToken="anySessionToken")
.build()
Si os fijáis, en la implementación del builder, he tomado la decisión de rellenar los valores con datos por defecto en los que simplemente me he preocupado de rellenar algo que cuadre con el tipo. En mi caso suelo usar el prefijo “any”, “irrelevant” o “arbitrary” como convención para indicar que en realidad ahí se puede poner cualquier cosa.
Ventajas
- Eliminamos boilerplate a la hora de inicializar entidades/value objects.
- Podemos ofrecer algunos métodos que añadan algo de sofisticación y semántica de negocio sobre los campos de la entidad.
- Nos evitamos tomar la decisión de qué valores usar para los campos que no nos interesan para nuestro caso concreto.
Inconvenientes
- Si hay que inicializar muchos datos, no nos ahorramos mucho código.
- La mayoría de las veces usamos semántica de campos de la entidad y no de negocio. Esto puede hacer que sea difícil comprender por qué rellenamos así nuestro objeto.
Mother objects
Están muy relacionados con el concepto de clases de equivalencia (si no lo conocéis, os recomiendo que investiguéis un poquito sobre ello ya que os dará vocabulario a lo que ya venimos haciendo por intuición). Los Mother Object nos ofrecen un catálogo de entidades con valores predefinidos para diferentes escenarios. De esta manera, nosotros, al escribir nuestro test, vamos a nuestro catálogo y cogemos el objeto que mejor nos venga para nuestro caso.
object UserMother {
private val arbitaryStringWithUUIDForm = "d019ab89-ac0a-4a65-962e-86fc20fca218"
fun givenAValidFullUser(
id: String = arbitaryStringWithUUIDForm,
email: String = "user@email.com",
role: Role = Role.ADMIN
): User {
return User(
id = id,
email = email,
firstName = "arbitrary First name",
lastName = "arbitrary Last name",
sessionToken = "",
imageUrl = "http://arbitraryImage.com/image",
roles = setOf(role),
enabled = true,
creationDate = DateTime(0).withZone(DateTimeZone.UTC)
)
}
fun givenAUserWithInvalidEmail(): User {
return givenAValidFullUser().copy(email = "invalidEmail")
}
fun givenADisabledUser(
id: String = arbitaryStringWithUUIDForm,
email: String = "user@email.com",
role: Role = Role.ADMIN
): User {
return givenAValidFullUser(id, email, role).copy(enabled = false)
}
fun givenAUserWithNoAvatar(
id: String = arbitaryStringWithUUIDForm,
email: String = "user@email.com",
role: Role = Role.ADMIN
): User {
return givenAValidFullUser(id, email, role).copy(imageUrl = null)
}
}
Como vemos, aquí pedimos usuarios desde el punto de vista más próximo al negocio. Cuando estamos escribiendo el test, no nos preocupamos de valores concretos, sino que pensamos en el tipo de usuario que nos haría falta para el escenario que vamos a probar. Es decir,
Ventajas
- Aportan mucha semántica.
- Obtenemos nuestros datos de pruebas con muy poco código.
- No tenemos que pensar en que implicaciones tiene usar unos valores u otros en cada test, porque ya lo hemos pensado al definir el método del mother.
Inconvenientes
- En la práctica, es difícil mantener organizado el mother y acabamos con métodos duplicados que devuelven objetos de la misma clase de equivalencia porque no hemos encontrado lo que queríamos. *En concreto he estado en un proyecto en el que había varios mothers para una misma entidad y que en la práctica nadie usaba ;(.
- Cuando estamos escribiendo un test y no tenemos un objeto del tipo que queremos, tendemos a escribir rápido y sin pensar mucho un método que nos cuadre por lo que los valores a veces no son los más adecuados.
Por otro lado, hay gente que opina, no sin razón, que esta abstracción le podría quitar valor a los tests como documentación ya que se añade un nivel de abstracción sobre qué significa, por ejemplo, que un usuario sea válido. No obstante, en mi opinión es todo lo contrario. Estás diciendo explícitamente qué significa que un usuario sea válido para ti, solo que no tienes que repetir esta definición una y otra vez a lo largo de todo el código (tengo pendiente otro post en el que cubriré esto con más detalle).
Generadores
Hay algunos ejemplos de tests concretos que si que requieren unos valores fijos y conocidos de antemano. Por ejemplo, si queremos hacer tests de snapshot, tendremos que conocer a priori los valores con los que vamos a ejercitar nuestro SUT, si no, es muy probable que nos fallen los tests en las aserciones.
Pero salvo para esos casos concretos, la mayoría de las veces, nos valdría con tener un valor cualquiera dentro de la misma clase de equivalencia. Para estos casos, yo suelo aprovechar la herramienta que nos proporcionan las librerías de Property Based Testing para implementar mis Mother Objects con datos aleatorios. Para mi esto tiene una implicación positiva, aunque es un arma de doble filo:
Tengo que dedicar un rato a pensar que forma tienen mis datos para modelar mis generadores.
Por ejemplo, si mi campo firstName es un String… ¿me vale cualquier string? ¿con cualquier juego de caracteres? ¿voy a permitir caracteres japoneses? Normalmente cuando decidimos nosotros los datos, no pensamos en esto y solemos buscar un ejemplo sencillo (total, cualquier string valdría), pero cuando usamos un generador, nos fuerza a pensar detenidamente en esto, ya que tendremos que decidir si generamos cualquier string o solo caracteres alfanuméricos, por ejemplo.
Si bien es cierto que esto puede suponer un sobrecoste, creo que merece la pena una vez tienes un poco de costumbre. En la práctica he logrado encontrar más fallos así. Además, aprovechando que ya tengo los generadores implementados, muchos tests los hago basados en propiedades mientras que otros los hago de forma tradicional aprovechando los mismos datos.
¿Cómo hago esto? Lo primero es poder obtener de manera sencilla un dato generado, en kotlin por ejemplo lo haría con una extensión:
fun <R> Gen<R>.sample(): R = this.random().first()
A partir de ahí, ya simplemente hago los generadores.
/*
De esta manera podemos sobreescribir algunos valores
y tenemos un comportamiento parecido al que usamos con el Mother Object
*/
class UserGenerator(
private val id: String? = null,
private val email: String? = null,
private val sessionToken: String? = null
) : Gen<User> {
override fun constants(): Iterable<User> {
return emptyList()
}
override fun random(): Sequence<User> {
val stringGenerator = Gen.alphanumeric(minLength = 1, maxLength = 256)
return generateSequence {
User(
id = id ?: Gen.uuid().sample().toString(),
email = email ?: stringGenerator.sample(),
firstName = stringGenerator.sample(),
lastName = stringGenerator.sample(),
imageUrl = stringGenerator.sample(),
sessionToken = sessionToken ?: stringGenerator.sample(),
roles = Gen.list(Gen.enum<Role>()).sample().toSet(),
creationDate = DateGenerator().sample(),
enabled = Gen.bool().sample()
)
}
}
}
/*
En lugar de implementar estos métodos como parte de UserGenerator, se los extiendo a Gen<User>
así si en algún momento tenemos una instancia del generador, no tenemos que preocuparnos de cómo la creamos.
*/
fun Gen<User>.enabled(): Gen<User> = this.map {
it.copy(enabled = true)
}
fun Gen<User>.enabledWithRole(role: Role): Gen<User> = this.map {
it.copy(roles = mutableSetOf(role))
}
fun Gen<User>.enabledWithRole(roleGenerator: Gen<Role>): Gen<User> = enabledWithRole(roleGenerator.sample())
* He dejado algunos comentarios en el código por si ayudan a comprenderlo mejor
Si quisiéramos usar estos generadores en nuestros test, simplemente tendríamos que hacer:
val enabledAdmin = userUserGenerator().enabledWithRole(Role.Admin).sample()
No parece excesivamente difícil, ¿no? :)
No obstante, yo lo que suelo hacer es esconder el uso de generadores en test que no son de propiedades y simplemente hago uso de estos generadores para implementar mis Mothers que quedarían así:
object UserMother {
/*
Cuando necesito datos que no varíen, por ejemplo para hacer Snapshot testing, uso valores fijos
y mi método lo documenta explícitamente con su signatura.
*/
fun givenAValidFullUserWithFixedValues(role: Role = Role.ADMIN): User {
return User(
id = "d019ab89-ac0a-4a65-962e-86fc20fca218",
email = "user@email.com",
firstName = "arbitrary First name",
lastName = "arbitrary Last name",
sessionToken = UUID.randomUUID().toString(),
imageUrl = "http://arbitraryImage.com/image",
roles = setOf(role),
enabled = true,
creationDate = DateTime(0).withZone(DateTimeZone.UTC)
)
}
fun givenAValidFullUser(role: Role = Role.ADMIN): User {
return UserGenerator().enabled().map { it.copy(roles = setOf(role)) }.sample()
}
fun givenAUserWithNoRoles(): User {
return UserGenerator().enabled().map { it.copy(roles = setOf()) }.sample()
}
fun givenADisabledUser(): User {
return UserGenerator().map { it.copy(enabled = false) }.sample()
}
}
Ventajas
- Al menos en mi caso, cuando estoy desarrollando el generador, me concentro y pienso exclusivamente cómo deberían ser los datos. Mientras que cuando creo un dato directamente en el test, no solía pensar tanto en ello y me fiaba más de mi intuición.
- Me ahorro decidir con qué dato concreto ejecutar los tests. Y esa decisión que ya no tengo tomar, hace que me de menos pereza escribir el test.
- Ejercitamos nuestros tests con un montón de datos diferentes y, creedme si os digo que he encontrado más de un bug gracias a esto.
Inconvenientes
- A veces podemos tener la sensación de tener flaky tests porque a veces funcionan y a veces fallan (en realidad suele ser que hemos encontrado un bug, así que podría considerarse ventaja :P).
- Los generadores pueden ser un poco más costosos de desarrollar que un Mother o un Builder.
- Al no tener conocimiento de los datos concretos, es posible que tengamos que replantearnos como hacer el test.
- Al ser datos generados aleatoriamente y no usar todo el stack de Property, es posible que nos cueste depurar el test en caso de error ya que los valores generados tienden a no ser user friendly.
Por aquí os dejo un ejemplo sobre cómo he usado yo esto:
@Test
fun `it should find the users by id when they're stored into the database`() {
val user = UserMother.givenAValidFullUser()
database.inTransaction {
userRepository.create(user)
val foundUser = userRepository.findById(user.id)
user shouldBe foundUser
}
}
Además, en el siguiente pantallazo podéis ver que he usado el método givenAValidFullUser() 40 veces. Esto quiere decir, que me he ahorrado pensar en que implica que un usuario sea válido y con todos sus datos 39 veces. Más las inicialización de 9 x 39 = 351 campos :S.
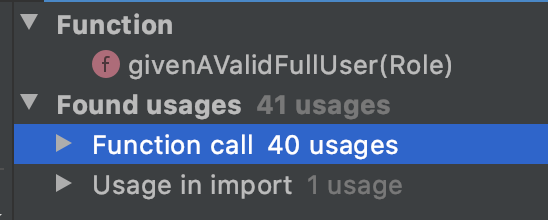
Y eso sin hablar de la pereza que nos daría tener que añadir un nuevo campo a la entidad User de nuestro proyecto. En ese momento es en el que podríamos pensar que:
hacer tests es una mierda… cambio un campo de nada y tengo que tocar en más de 40 sitios.
Sin embargo, si nos lo montamos bien, la situación puede ser más del estilo de:
voy a ejecutar toda la suite a ver si he roto algo con este cambio.
¡Y el gustito que da cuando un test falla después de un cambio que efectivamente había roto algo, no tiene precio!
Y tú, ¿cómo resuelves este problema?