Reduciendo boilerplate en los mocks
En el título hablo de mocks porque es lo socialmente aceptado, pero en realidad de lo que quiero hablar en este apartado es de acotar el scope a nuestras necesidades.
La primera decisión que tomo (a veces de manera inconsciente) es acerca del tamaño de mi SUT. Es decir, qué parte de mi código de producción quiero probar.
Nos han insistido muchísimo en que deberíamos tratar de implementar muchos tests unitarios, menos de integración y menos aún de sistema/UI/aceptación (la famosa pirámide de los tests). Esto es fundamentalmente porque cuanto más grandes sean los test, más costosos nos resultan. Habitualmente son más costosos de implementar, mantener, ejecutar, comprender o depurar. Pero es que además, cuanto mayor sea la cantidad de código a probar, mayor complejidad ciclomática tendrá, es decir, más posibles caminos que probar con sus correspondientes casos de prueba. Y en general, nos resultará más fácil desarrollar 3 casos de prueba para 10 bloques de código “independientes” que 30 casos de prueba para un solo bloque.
Una vez explicado esto, os intentaré contar mi proceso mental y las decisiones que tomo yo cuando me toca probar. Como siempre, es posible que diga cosas que no encajen con vuestra experiencia. Esto sería lo normal, en primer lugar, porque puedo estar equivocado y en segundo lugar, porque creo firmemente que hay más de una forma de hacer las cosas.
No usar dobles de prueba
Del mismo modo que no implementar una funcionalidad concreta es la mejor manera de mantenerla simple y mantenible. No se me ocurre mejor manera de reducir código de dobles de pruebas que no usándolos :P.
Pero… acabo de hablar de la importancia de hacer muchos tests unitarios :S. Si, pero de lo que no hemos hablado es de que la definición de unitario ha ido cambiando con el tiempo. Quienes la aprendisteis hace unos años, seguramente tendréis en mente probar métodos de una sola clase.
Esto tiene varias ventajas:
- No tengo que pensar en el scope porque ya lo tengo pre-decicido.
- Tengo trazabilidad entre el código de producción y el de test. Y la trazabilidad es una cualidad importantísima en el software.
- Los IDEs siguen esta convención y me ayudan a navegar entre test y código de producción.
- Tenderemos a tener un tamaño manejable de código que probar (salvo que nuestro código de producción tenga mala leche).
Pero también tiene algunos problemas:
- Tendemos a no tener ninguna prueba que verifique la interacción entre componentes.
- Dedicamos la mayor parte del tiempo a definir dobles de pruebas más que a diseñar la prueba en si.
- Si la signatura de nuestros métodos no es explícita, tendremos que realizar las aserciones sobre la interacción entre componentes por lo que nos tocará sobreespecificar (verificar interacciones con los mocks). Por si te interesa, en un post anterior ya hablé un poco sobre este tema.
- Cuando vamos teniendo experiencia con los mocks, empezamos a no preocuparnos por ciertos datos y se pierde el valor de documentación de los test. (Lo ilustro con un ejemplo que se entenderá mejor:)
@Test(expected = ValidationError::class) fun `test user when validator doesn't pass will fail`() { val user = givenAValidUser() /* como se puede ver, configuramos el mock para que falle, aunque tenemos una instancia válida de usuario. Esto despistará a las personas menos experimentadas y hará que disminuya el valor del código como documentación. */ when(userValidator).validate(user).thenThrow(ValidationError()) createUser(user) }
Sin embargo, esta tendencia está cambiando y ahora tenemos que otro criterio socialmente aceptado que se suele tomar para hablar de unidad es que mi trozo de código no hable con sistemas externos.
En definitiva, lo que hace que mis tests sean más inestables y más complejos suele ser la interacción con sistemas externos, por lo tanto si la evitamos, tendremos tests que no son unitarios, pero que lo parecen :)
Si conseguimos tener un test que ejercite mucho código, pero que mantenga las propiedades F.I.R.S.T. podemos obviar el tamaño de nuestro SUT.
Creo que se verá mejor con un ejemplo. Imaginaos el registro (simplificado) de un servicio cualquiera. Desde la vista llegarán los datos del usuario, el sistema lo validará y de ser así lo creará e iniciará el proceso de verificación del email. Este código podría tener un grafo de dependencias así:
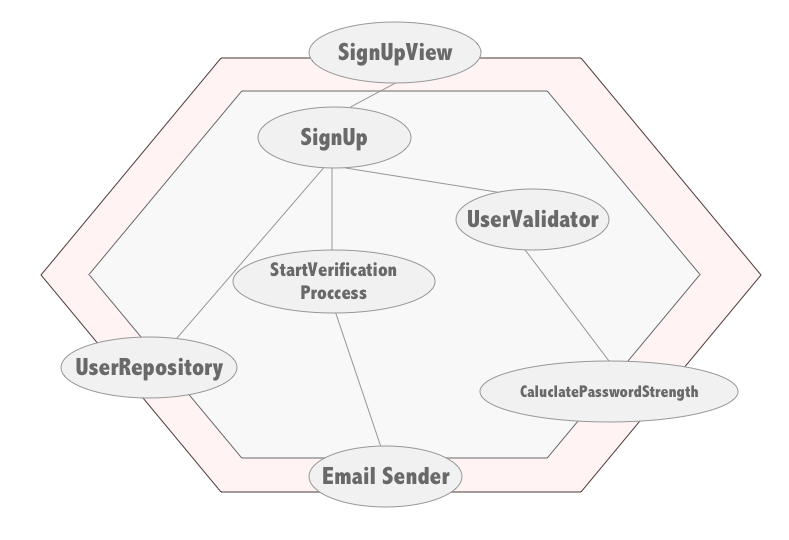
Ahora nos tocaría elegir el scope de nuestros tests. Yo por un lado probaría de manera independiente el código que interactúa con el exterior, que en este caso son todos los nodos hoja, más el nodo de la vista. Es decir, el Repositorio, el EmailSender, CalculatePasswordStrength que hace uso de un API de otro servicio, y la vista SignUpView.
Os adelanto la conclusión por si no queréis leer todo el razonamiento:
- Probaría todos los adapters por separado. Es decir, una clase de test para UserRepository, EmailSender y CalculatePasswordStrength.
- Probaría la vista SignUpView reemplazando el caso de uso SignUp por un doble de pruebas (seguramente un mock).
- Probaría el caso de uso SignUp con instancias reales (pero aisladas) de UserValidator y StartVerificationProcess y tendría que pensar si usar una instancia real de UserRepository contra una base de datos ligera (SQLite o H2 en memoria) o usar un doble de pruebas para el repositorio.
Por si os interesa el proceso mental del caso de uso os dejo mi razonamiento:
Adapters
Al no tener control sobre el sistema externo, siempre existe la posibilidad de que no llegue a comprender bien cómo funciona dicho sistema, por lo tanto no es buena idea reemplazarlo por un doble de pruebas. Por lo tanto prefiero probar esa parte atacando al sistema real (o lo más real posible). A pesar de que en general la capa de “Adapters” debería ser razonablemente delgada, estos tests son potencialmente difíciles, ya que generalmente requerirán infraestructura adicional y seguramente sean muy lentos. No obstante, es habitual que estos tests aporten mucho valor, precisamente por lo que comento de que muchas veces nos tenemos que integrar con sistemas que no terminamos de comprender del todo. Con documentación laxa (o inexistente) y con poco tiempo para aprender su funcionamiento. Aquí tenemos dos fuentes de fallos:
- Los debidos a la programación en sí.
- Los debidos a la falta de conocimiento del sistema externo.
La vista
En general la vista tiene una problemática asociada que hace que prefiera reducir el scope lo más posible para no ir sumando problemas.
- Generalmente para probar la vista tendremos que buscar la manera de levantar el stack completo. Esto hace que los tests sean lentos (si encima le añadimos un scope grande podrán ser más lentos).
- El hecho de que sean lentos hace que nos de pereza ejecutarlos y depurarlos, por lo que cuanto más simple se mantengan menos posibilidades de que fallen :).
- No solemos estar acostumbrados a hacer UIs accesibles desde el punto de vista de nuestros tests, por lo que la interacción del test con el SUT es potencialmente tediosa.
- Una buena técnica de aserción para estos tests podría ser Snapshot o Screenshot. Esta técnica es tan potente como inflexible, en el sentido de que cualquier mínimo cambio en la UI rompe el test. No obstante al ser fácil de ejecutar los tests en modo “recording” para “arreglar todos los tests rotos” puede hacer que no siempre verifiquemos si el test se ha roto por el cambio del código de producción o porque efectivamente había un fallo. Por lo tanto mantener el SUT pequeño, en mi opinión, minimiza este problema.
El caso de uso y sus dependencias
- El componente que ofrece la puerta de entrada al Caso de Uso lo voy a querer probar ejercitándolo directamente, es decir, la ejecución de mi test va a tener la llamada
signUp(user)seguro. - Me planteo si las dependencias las probaré por separado o como parte de este test.
- Me planteo cuanta casuística añade cada dependencia a mi test. Por ejemplo StartVerificationProcess no parece que tenga flujos alternativos, por lo tanto no añade escenarios nuevos a mi prueba. Sin embargo, el componente UserValidator, podría añadir bastantes casos nuevos del estilo, “los campos son inválidos”, “la password es muy débil”, “me falta información obligatoria”, etc.
- En caso de que añadan mucha casuística nueva que hagan que pierda el foco de mi caso de uso, me planteo seriamente probar el componente por separado. Aunque en este ejemplo en concreto, los errores de validación suelen ser fáciles de agrupar y probar con un test parametrizado (esos grande olvidados :S). Pero os dejo un ejemplo en java con JUnitParams:
@Test
@Parameters(source = InvalidUserDataProvider.class)
public void whenWithNamedClass_thenSafeAdd(
User user, ValidationError expected) {
try {
signUp(user);
fail();
} catch(ValidationError e) {
assertEquals(expected, e);
}
}
public class InvalidUserDataProvider {
public static Object[] provideBasicData() {
return new Object[] {
new Object[] { userWithInvalidName, ValidationException("invalid name") },
new Object[] { userWithInvalidPassword, ValidationException("invalid password") },
new Object[] { userWithInvalidEmail, ValidationException("invalid email") }
};
}
}
- En caso de la dependencia se use en muchos otros sitios, también me haría cuestionarme si probarla por separado, de esta forma gano trazabilidad (sé que test prueba ese componente) y evito probar N veces el mismo componente. Me intento explicar mejor: imaginaos que tengo 7 casos de uso que usan la clase UserValidator si en cada test de cada caso de uso ejercito dicho validador real y cambio la lógica de validación, tendré que cambiar muchos tests.
En este caso en concreto seguramente me plantearía probar lo siguiente:
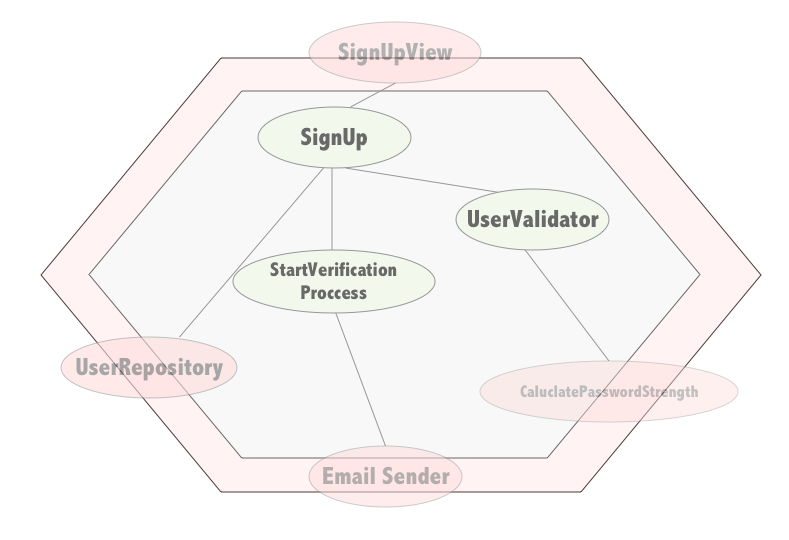
Además por la forma que tenemos de programar, muchas veces tendremos un montón de dependencias que ofrecen utilidades que aportan poca semántica de negocio. Son constructos artificiales que nos ayudan con nuestro trabajo. En ese sentido, los casos de uso (que serían los que contarían la historia más fiel desde la perspectiva de negocio) son meros orquestadores por lo que sus tests, a pesar de ser el punto de entrada a nuestro “modelo de negocio” tiene pruebas sobreespecificadas que aportan poco valor real, que además son frágiles y tediosas de escribir.
Por otro lado, un problema derivado de hacer este tipo de tests, es que, si no utilizamos ningún mecanismo que cree los objetos por nosotros, puede ser bastante tedioso.
Os dejo dos ejemplos con y sin mecanismos de creación:
fun `inicializando el SUT a pelillo`() {
val calculatePasswordStrength: CalculatePasswordStrength = mock()
val userValidator = UserValidator(calculatePasswordStrength)
val emailSender: EmailSender = mock()
val startVerificationProcess = StartVerificationProcess(emailSender)
val userRepository: UserRepository = mock()
val signUp = SignUp(
userValidator = userValidator,
userRepository = userRepository,
startVerificationProcess = startVerificationProcess
)
}
fun `inicializando el SUT con un injector que nos permita reemplazar dependencias`() {
val calculatePasswordStrength = injector.mockDependency<CalculatePasswordStrength>()
val emailSender = injector.mockDependency<EmailSender>()
val userRepository = injector.mockDependency<UserRepository>()
val signUp = injector.getInstance<SignUp>()
}
Parece que la segunda opción es muuucho más cómoda que la primera, ¿no? La cuestión es que necesitamos tener un inyector de dependencias bien configurado y dotarlo de la capacidad de reemplazar dependencias en runtime y esto no siempre es trivial.
Ventajas:
- Con un solo test cubrimos bastante código
- No solo probamos los componentes por separado, sino que también probamos su interacción con otros componentes.
- En algunos casos evitamos código de configuración de mocks.
- En mi experiencia este tipo de tests encuentran más fallos en tiempo de implementación y de regresión.
Inconvenientes:
- Como vemos, inicializar el SUT puede ser complejo.
- Podemos llegar a tener muchísimos casos de prueba y es fácil que se nos olvide cubrirlos todos.
- Si nuestro test falla, puede que nos cueste cierto trabajo entender por qué ha fallado.
- Es posible que nuestro test sea algo más complejo así que debemos tener especial cuidado en tratarlo como cualquier otro código.
Dummies o Fake implementations
Obviando a quienes programéis para iOS donde creo que no existen mecanismos de mocking o en JS que muchas veces usáis este recurso, la mayoría, tendemos a recurrir siempre a los mocks. Usando para ello una librería que nos permite definir un comportamiento enlatado para nuestros componentes. Sin embargo hay una opción mucho menos sofisticada y que a veces es mucho más cómoda y más funcional. Hacer una implementación dummy súper simplificada que podamos controlar.
Os dejo un ejemplo que no falta en ninguno de mis proyectos. El DummyTimeProvider. Para quienes estéis menos familiarizados con esta problemática, la cuento muy por encima. Hacer un new Date() suele ser bastante mala práctica de cara a hacer un código testable. La razón es que perdemos el control sobre la fecha, por lo tanto hay funcionalidad que directamente no podremos probar (por ejemplo algo que debería suceder a determinada hora). Las fechas suelen ser también el motivo de que muchos tests se rompan con el cambio de año, o en años bisiestos, etc.
¿La solución? Un componente que nos de la hora y que podamos reemplazar en tiempo de test. El archiconocido TimeProvider
open class TimeProvider {
open fun now(): DateTime {
return DateTime()
}
}
Si quisiéramos mockear este componente, acabaríamos con nuestro código plagado de este trocito:
val timeProvider: TimeProvider = mock()
val componentThatUsesTime = ComponentThatUsesTime(timeProvider)
fun `test that mock time`() {
whenever(timeProvider).now().thenReturn(DateTime(1234))
}
Otra alternativa sería implementar un dummy:
class DummyTimeProvider(private var reference: DateTime = DateTime(0).withZone(DateTimeZone.UTC)) : TimeProvider() {
override fun now(): DateTime {
return reference
}
fun withTime(reference: DateTime) {
this.reference = reference
}
}
Que se usaría así:
val timeProvider = DummyTimeProvider()
val componentThatUsesTime = ComponentThatUsesTime(timeProvider)
fun `test that mock time`() {
timeProvider.now()
//o si queremos cambiar la hora:
timeProvider.withTime(DateTime(1234)).now()
}
Como vemos, lo que nos ahorraríamos sería la definición del comportamiento del mock. No parece mucho, pero a mi, personalmente me da una pereza horrorosa escribir ese código :S.
“Mother” Mocks
¿Por qué me da tanta pereza definir el comportamiento de un mock? Hay dos razones principales:
-
El código en si me parece aburrido de escribir. Por muy semántico que sea me parece verboso y ni usando los live templates del IDE se me pasa la pereza.
-
Cada vez que defino un mock tengo que tomar una decisión; ¿debería esperar unos parámetros fijos o acepto cualquier cosa? ¿estaría bien verificar la interacción con el mock o si mi método devuelve lo esperado asumo que se ha llamado?
No obstante los mocks son una herramienta muy potente y muy usada así que vamos a darle una vuelta para ver si podemos usarla de manera más cómoda. Aunque supongo que con el nombre de “Mother” ya os haréis una idea de por donde van los tiros.
Para darle un poco de valor, imaginemos que tenemos un componente UserRepository a cargo, entre otras cosas, de recuperar usuario de la base de datos. Es susceptible que este método lo tengamos que mockear en un montón de tests ya que en mayor o menor medida muchos de nuestros casos de uso podrían necesitar de ese usuario. Tendremos dos casuísticas:
whenever(userRepository.findById(any())).thenReturn(foundUser)
//or in case the user is not found
whenever(userRepository.findById(any())).thenReturn(null)
/*
Depending on the mock library, in case we return null,
we could skip this line as mocks will return as default result.
However making it explicit could work as documentation.
*/
Como vemos, aquí ya he tomado la decisión de no verificar el id del usuario que busco en la llamada del mock. Lo he hecho por varias razones (muy cuestionables, pero a mi me valen), la primera es que no me gusta sobreespecificar la interacción porque sino acabo con tests muy sensibles a cualquier cambio. Como cuento con las code reviews como mecanismo de seguridad, confío en que, si me equivoqué con el argumento de llamada, se verá en la revisión o seguro que salta en algún que otro test. Además he de confesar que me da pereza escribir algo que no sea any() ahí (sí, soy un flojo a veces y dejo que la pereza decida por mi). Por último, el código que suelo escribir suele tener métodos cortos y con pocos argumentos por lo que rara vez se da el caso de que confunda un argumento por otro, no obstante en casos donde hay argumentos con nombres muy parecidos (que al autocompletar con el IDE me pueda equivocar) o métodos más complejos, sí que me planteo verificar los argumentos. La cuestión es que esa decisión pasa completamente desapercibida para el resto del equipo y lo mismo les gustaría opinar al respecto.
Pero, como definir el comportamiento de un mock, no nos suele llevar más de una línea de código, tiende a no importarnos escribirla una y otra vez. Sin embargo, esto tiene algunos problemas:
- Si, por lo que sea cambia la signatura del método mockeado habrá que cambiarlo en un montón de sitios.
- No describe muy bien lo que pretende hacer.
- Esto causa que cuando definimos comportamiento de varios mocks en un test, tiende a volverse poco legible.
Yo normalmente lo soluciono encapsulándolo en un método:
object UserRepositoryMockedBehavior {
fun givenUserIsFound(repository: UserRepository, foundUser: User) {
whenever(repository.findById(any()).thenReturn(foundUser)
}
fun givenUserIsNotFound(repository: UserRepository){
whenever(repository.findById(any()).thenReturn(null)
}
}
//o como clase si no queremos pasar el mock en cada método:
class UserRepositoryMockedBehavior(private val mockedRepository: UserRepository) {
fun givenUserIsFound(foundUser: User) {
whenever(mockedRepository.findById(any()).thenReturn(foundUser)
}
fun givenUserIsNotFound(){
whenever(mockedRepository.findById(any()).thenReturn(null)
}
}
Esta aproximación resuelve los problemas planteados anteriormente. Peeero, me resulta un poco rollo tener que andar pasando los mocks de un lado a otro así que os cuento cómo lo hago yo cuando el lenguaje lo permite.
Pimp my library
Es una pijada, pero cuando el lenguaje lo permite, me gusta atribuirle ese comportamiento de configuración de Mock a la propia clase que mockeo. Es decir:
fun UserRepository.givenUserIsFound(found: User = UserGenerator().sample()): User {
whenever(this.findById(any())).thenReturn(found)
return found
}
Esto en un test se usaría así:
class UserServiceTest {
private val userRepository: UserRepository = mock()
private val userService = UserService(
userRepository = userRepository
//... add other dependencies
)
@Test
fun `should work fine when user is found`() {
val foundUser = userRepository.givenUserIsFound()
//implement the test assuming user is found
}
}
Como bola extra, además he hecho uso de los generadores para no tener que andar pensando en qué usuario se devuelve (aunque se puede sobreescribir si hace falta).
Para mi esta aproximación tienen una ventaja pequeñina y una grande:
- La pequeñina es que tenemos muy cerca el código de mocks y el código de producción que se mockea.
- La ventaja grande es que el IDE te autocompleta el método que configura el mock y eso es especialmente útil cuando tienes muchos comportamientos definidos para ese mock, porque en mi experiencia tendemos a no invertir tiempo en buscar si alguien ya ha implementado el comportamiento y acabamos escribiéndolo de nuevo. Pero al tenerlo en el autocomplete, me resulta más fácil encontrarlo.
Conclusiones
Si has llegado hasta aquí, no me queda más que pedirte disculpas por semejante post largo. Al final siempre se me va la mano, sorry. Pero no me quiero despedir sin hacer un brevísimo resumen.
- La decisión sobre el scope de nuestro test es importante.
- Que los mocks sean fáciles de configurar no implica que debamos conformarnos con escribir una y otra vez la misma línea. Ésta esconde bastantes decisiones implícitas.
- Configurar nuestro SUT es tedioso así que tratemos de reutilizar código y decisiones previas. Si hay más de un miembro en el equipo con criterio diferente, estas abstracciones fomentan la conversación para llegar a un consenso.
- Toma las decisiones que encajen mejor con tu problema y experimenta. No hace falta que lo diga ningún gurú para que a tu equipo le funcione.
Y tú, ¿como resuelves este problema?